dedications, an exercise
Created in Spring 2026.
— Ralph Waldo Emerson
In its 2025 Year in Review, Goodreads reports that I read 6,139 pages—30 books. This is just one instance of the now-familiar genre of data-aggregation-as-bite-sized-shareable-graphic.This year alone, I received year-in-reviews for music streamed, video games played, professional profiles browsed, rideshares requested, cuisines tried. Why so many?
— X user @schizohustler, Dec 3, 2025 [source]
“Data” is “accurate”, like a looking glass that does not flatter. This perceived neutrality helps explain why we love sharing year-in-reviews, and why platforms continue to produce them. Yet at a moment where data is increasingly used for surveillance, prediction, and potentially behavior manipulation, I grow critical of data aggregation.
This exercise seeks to represent my reading experience in a way that refuses data aggregation.
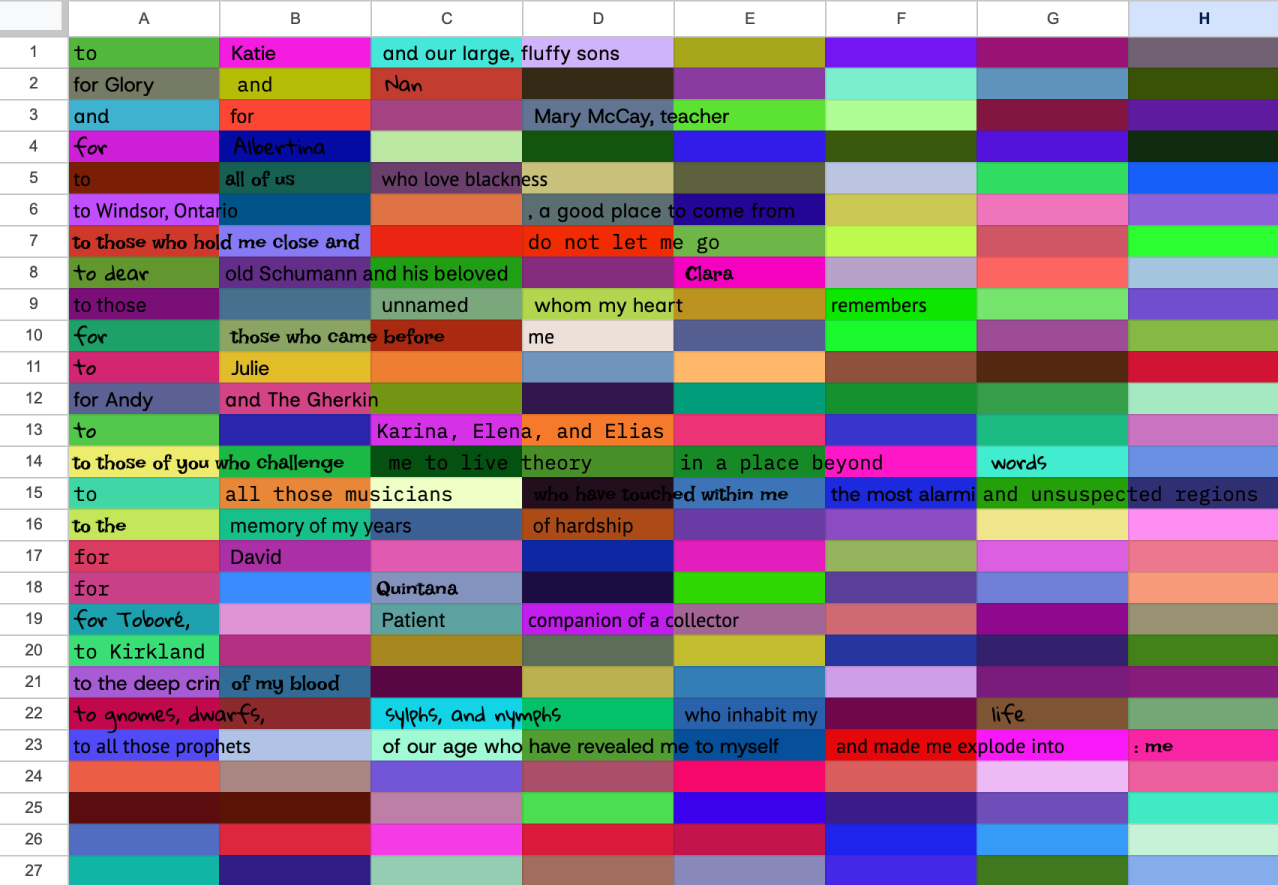
[1] I went through every book I read in 2025 and logged its dedication. Dedications fascinate me. Not all books have dedications. They are opaque, privately meaningful only to the writer. No doubt often sentimental, rarely indexed, and almost impossible to reverse-search, dedications gesture towards the labor of writing and the intimacy of reading that remain (yet) unoptimized for algorithms. I tokenized these dedications into clauses and reorganized them at random.
[2] I turned towards the spreadsheet as a platform ([a] as in IDE [b] as in stage). I scattered the texts across rows, intentionally without rationale.
[3] I employed a script to randomly select fonts and cell colors. I let the machine complete the ‘visualization’, resulting in a fittingly opaque graphic.
In pursuing randomness, encroaching on the domain of the machine, and misusing my tools, this exercise rejects the clarity promised by year-in-review metrics to embrace partial legibility.

